


AI Alignment Talk from Japan No.11 [Event Report] ICRES 2024 学生セッション
ライター:泉川茉莉

AI Alignment Talk from Japanは先日、慶應義塾大学で開催された国際ロボット倫理および基準会議シリーズ(ICRES 2024)にて学生セッションを実施しました。「AIアラインメントの現在と未来:多様な利害関係者による倫理およびガバナンスの課題」(原文:Student Session on The present and the future of AI Alignment: Multi-stakeholder ethical and governance challenge)と題したセッションは、AIアラインメントに対する認識を高め、より多くの利害関係者がこの分野に関与することを目的として企画されました。その目標を達成するために、本セッションでは、技術的および政策的視点からAIアラインメントの現状、課題、および将来の方向性を探りました。
セッションの前半では、機械論的解釈可能性および日本のAIガバナンスについての理解を深めるための講義を行い、後半では参加者全員による自由討論を実施しました。セッションは理論的基盤、倫理的考察、政策的影響、そして利害関係者の視点を通じて、AIアラインメントに関する包括的な理解ができるよう構成されました。
講演者には、AI Alignment Network(ALIGN)の研究フェローであり、東京大学の修士課程の高槻瞭大氏と、AI Safety Tokyoの理事であり、Noeon Researchのコミュニケーションオフィサーであるブレイン・ロジャース氏の2名をお招きしました。今回はイベントレポートとして、学生セッションの内容と、Key takeawayを振り返っていきます。
高槻瞭大氏:機械論的解釈可能性とAIアライメント
機械論的解釈可能性への導入
高槻氏は、AIモデルを訓練することの難しさを、子犬のトイレトレーニングに例えて説明した。子犬のトイレトレーニングと同様に、AIモデルの意図しない行動を避けるためには、適切な監督が重要である。高槻氏は、AIモデルが適切に訓練され、望ましい結果を出力するためには、AIモデルの内部構造を理解することが重要であるとした。
現状のAIモデルの訓練における課題
監督があるにも関わらず、報酬機能の欠陥により、AIモデルが予期せぬ判断をすることがある。これらの例として、高槻氏は、Specification gaming(文字通りの目的は達成しているが、本来の意図は達成しない行動)やJailbreaking(監督機能をすり抜けて、本来の目的に反する決定を下すなど)を挙げた。ここでも、機械学習モデルの内部構造を理解し、上記の問題を防ぐリバース・エンジニアリングを行うことの重要性を語った。

機械論的解釈可能性の技術
機械論的解釈可能性を実現するために活用される技術が取り上げられた。現在も使われている手法の一つとしては、最適化による特徴量の可視化が紹介された。これは、AIモデルの特定の要素(例えばニューロン)が何を検出するのかを探るために、入力を変化させながら活性化を最大化しようとする手法だという。この手法は、OpenAIの研究者も活用しているもので、これによって、曲線や周波数のコントラスト、車、といった様々な特徴量を検出するための回路やサブネットワークが特定されている。
多義的ニューロンの課題
機械論的解釈可能性において課題として、複数の特徴量によって活性化される多義的ニューロンが紹介された。多義的ニューロンは、重ね合わせと呼ばれる現象によって説明できる。各層で、次元数以上の特徴量を表現する多義的ニューロンはAIモデルのリバース・エンジニアリングの障壁となる。その解決策としては、AIモデルの中間層表現を高次元空間に疎にエンコードし、一義的ニューロンによる表現を経て、元の中間層表現をデコードするようなスパース・オートエンコーダが紹介された。
今後の展望
今後の展望として、高槻氏は機械論的解釈可能性の拡張可能性(スケーラビリティ)と、回路発見の自動化への取り組みについて述べた。また、スパース・オートエンコーダに関するAIベンチャーによる有望な取り組みについても言及した。最後に、AIモデルの内部構造を理解するだけでは不十分であり、AIの安全性を確保するための法的枠組みやより安全なメカニズムも必要であると強調した。技術的理解と規制措置の組み合わせは、AIの責任ある発展にとって極めて重要である。

ブレイン・ロジャーズ氏:日本のAIガバナンス
AI規制の概要
ブレイン氏の講義は安全なAI開発をするためのAI規制の役割についての説明から始まった。同氏は、国家規制、共同規制(特定分野の当事者に対して法に定められた目的の達成を委ねる)、自主規制を含む様々な規制の種類を紹介した。
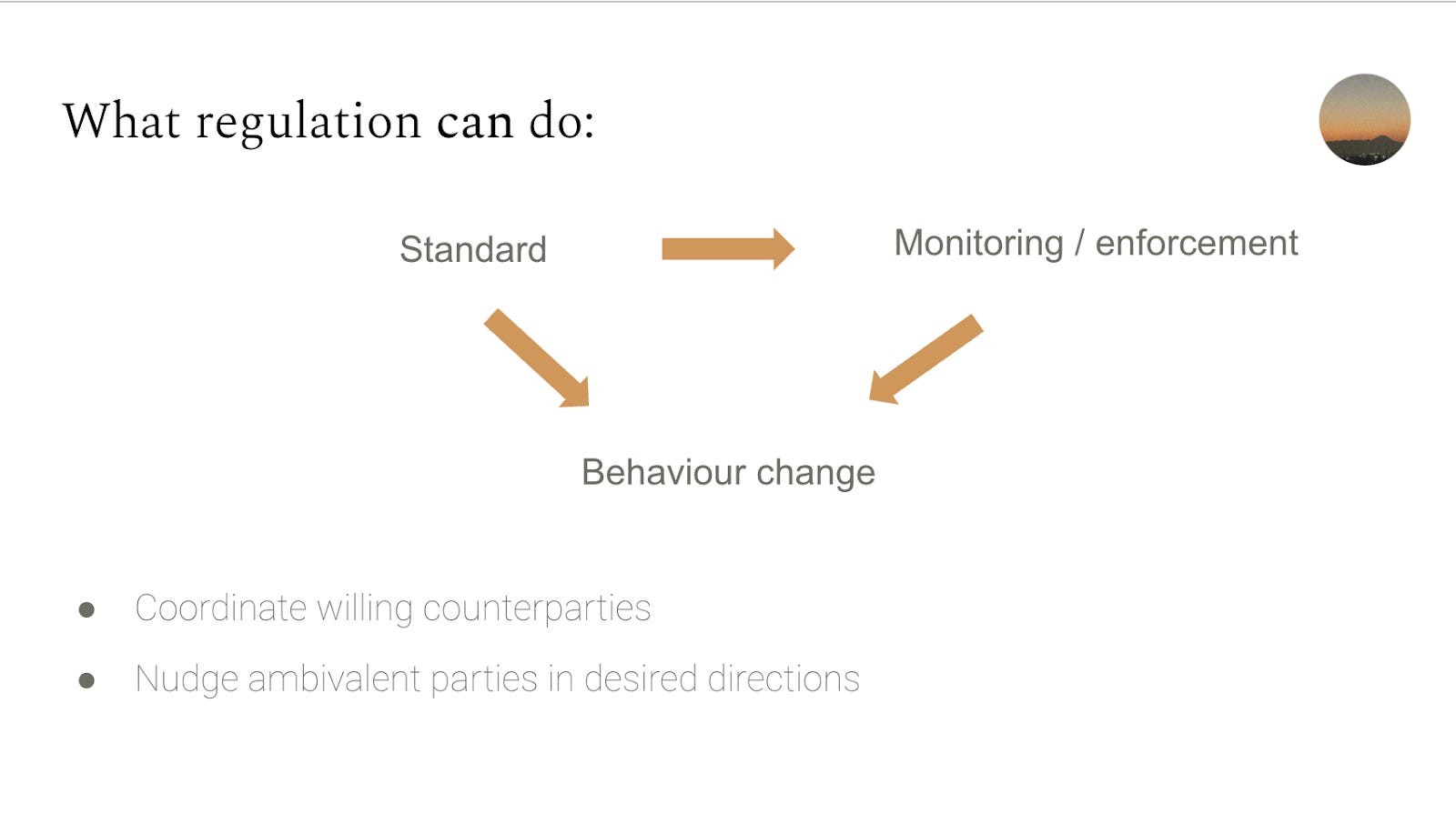
日本のAI規制アプローチ
日本は、COVID-19対応で示されたように、厳格な法的執行を伴わないガイドラインの発行など、ソフト・ローのアプローチを好む傾向にある。ブレイン氏は、AIチップに対するソフトローのグローバルな利用と、AI関係者に指針を提供する広島AIプロセスについて言及した。
AIにおける自己規制
ブレイン氏は、アルコール飲料業界などの他の業界におけるように、法的強制力なしに企業自身が基準を定める自主規制について、AIにも適用できると述べた。Anthropic、Google DeepMind、OpenAIなどの企業からの自主規制のフレームワークの例を示し、AI業界が効果的に自主規制を行えることを説明した。
AI規制に関する考え方
レッセフェール(Laissez-faire、自由放任主義)から強制的なアプローチまで、AI規制に関する様々な視点が紹介された。ブレイン氏は、効果的な加速主義、AI保護主義、ネオ・ラダイト主義といった概念を説明した。日本のAI政策は、安全性の重要性を認めつつ、イノベーションとのバランスを取ることを目指しているため、効果的な加速主義の分類に位置付けられると考えられる。

AI事業者ガイドライン
今年発表されたAI事業者ガイドラインの詳細が説明された。このガイドラインは、課題に対処し実装例を提供することで、適切なAI活用を促進することを目的としている。ガイドラインには法的な拘束力がなく、自主的なものである。ガイドラインは、透明性とステークホルダーの関与に重点を置いている。
責任あるAI推進基本法
ブレイン氏は、AIの利益とリスクのバランスを取ることを目指す、責任あるAI推進基本法を紹介した。AI基盤モデルを開発する企業が実施しなければならない対応を概説した。これらの措置は、米国政府に対して行われた自主的なコミットメントと一致している。さらに、この法律は「ソフトローからハードローへ」のアプローチを代表するもので、必要に応じて規制の監督を段階的に強化していくものであると述べた。
インタラクティブセッション
シナリオベースの議論
インタラクティブセッションでは、参加者に架空のシナリオが提示され、与えられた選択肢から行動方針を選んだ上で、議論をした。このアクティビティでは、AIアライメントとガバナンスに関する参加者同士の意見交流を目的とした。
シナリオ1:金融システムにおけるAIバイアス
このシナリオでは、銀行融資のリスク評価に用いるAIシステムに、意図しないバイアスが発見されたと仮定した。参加者は当該AIシステム開発企業の責任者として、倫理性を確保するために本システムの導入を遅らせるか、予定通り導入しながら段階的に倫理問題に対処するかを選択した。このシナリオは、市場機会と倫理的考慮のバランスをとる難しさを浮き彫りにした。

シナリオ2:災害対応におけるAI
別のシナリオでは、参加者が災害に対処する地方政府の役人の立場に立ち、災害シナリオで、機械論的解釈可能性が確立していないAIの決定を覆すかどうかを考えた。このシナリオは、人間による監視とAIの自律性の間の緊張関係を探り、状況に応じた意思決定の必要性、そして、AIがどこまで人間の価値観に整合していればそのシステムを信頼できるのかを考える機会となった。

まとめ
2つのゲスト講義は、AIにおける機械論的解釈可能性と日本におけるAIガバナンスの現状について包括的に学べる貴重な機会となった。機械論的解釈可能性はAIモデルの動作を理解するために重要である。一方で安全性を確保しながらイノベーションを促進するために、日本のAIガバナンスの状況は引き続き注視していきたい。インタラクティブセッションは、AIアライメントが不完全な中で、各アクターが直面し得る倫理的・政策的ジレンマを浮き彫りにした。総じて、本セッションでは、AIアライメントの前進には、技術的理解と政策面の対応を組み合わせたアプローチが必要であることがわかった。
謝辞:
ICRES 2024への参加をご支援くださった山川宏様、丸山隆一様、一般社団法人AI Alignment Networkの皆様に感謝申し上げます。